[WWDC17] 자연어 처리
NSLinguisticTagger 에 대한 내용입니다.
현재는 Deprecated 되었으므로, Natural Language Framework 을 참고해주세요.
올해 WWDC에서 애플은 애플의 인공지능에 대한 많은 홍보를 했고, 해당 기술들을 선보였습니다.
타사의 인공지능과 애플의 인공지능에 가장 큰 차이점을 말하라면, 애플은 모든 처리를 디바이스 내에서만 한다는 점입니다. 서버로 데이터를 보내지 않기 때문에, 보안과 프라이버시 걱정을 덜 수 있습니다.
인공지능 기술들 중 가장 기본적인 자연어 처리에 대해 알아보겠습니다.
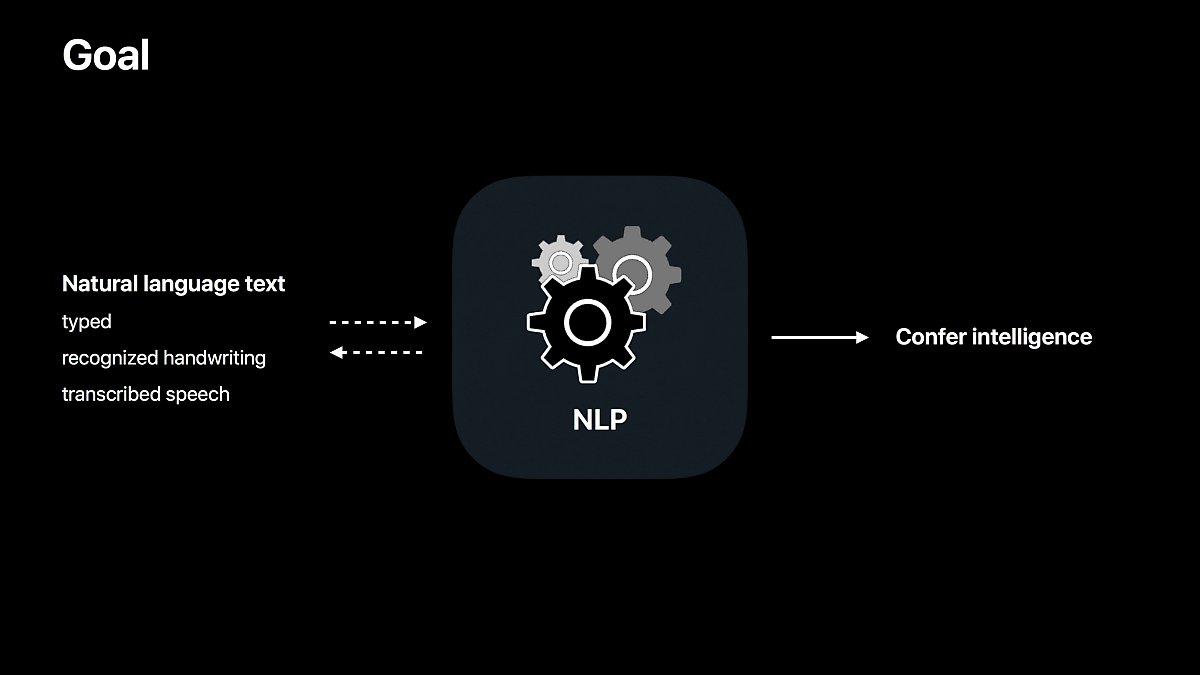
애플의 자연어 처리 엔진은 텍스트, 손글씨, 음성 등으로부터 얻은 텍스트 정보를 가공하기 쉬운 정보로 변환해 주는 역할을 합니다.

자연어 처리 엔진은 이미 애플 제품의 많은 곳에서 쓰이고 있습니다.
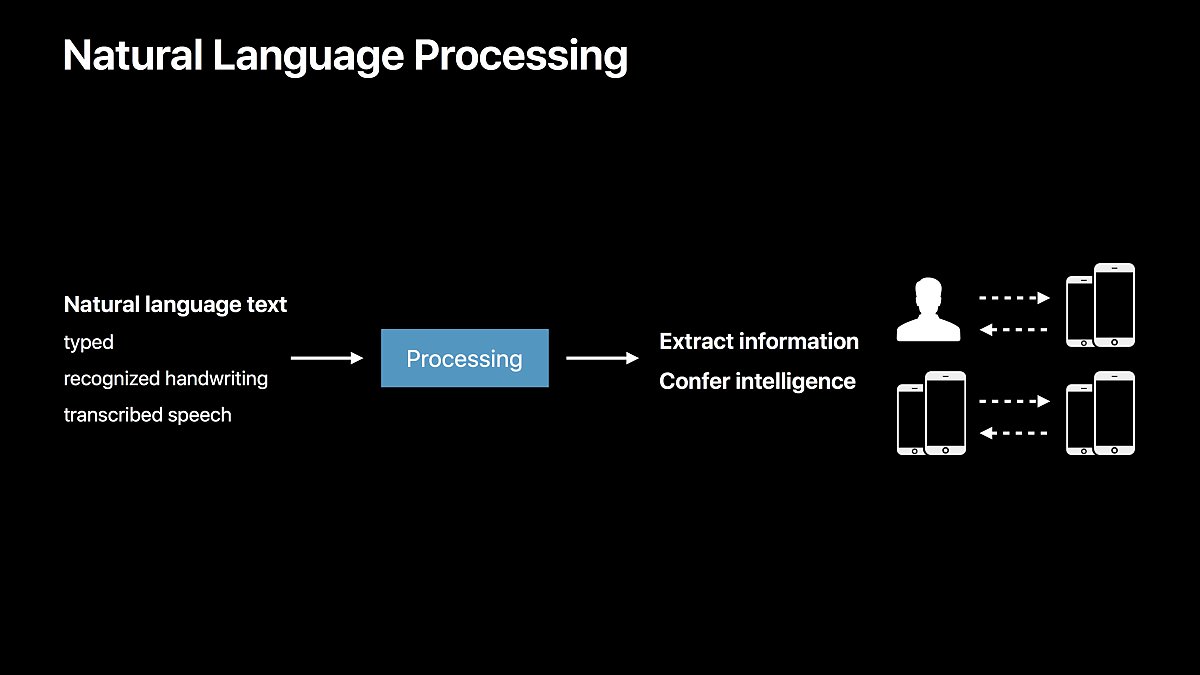
자연어 처리로 얻은 정보들은 디바이스와 유저간의 상호 작용뿐만 아니라, 디바이스 내에서도 앱 간의 정보처리에 도움을 줍니다.
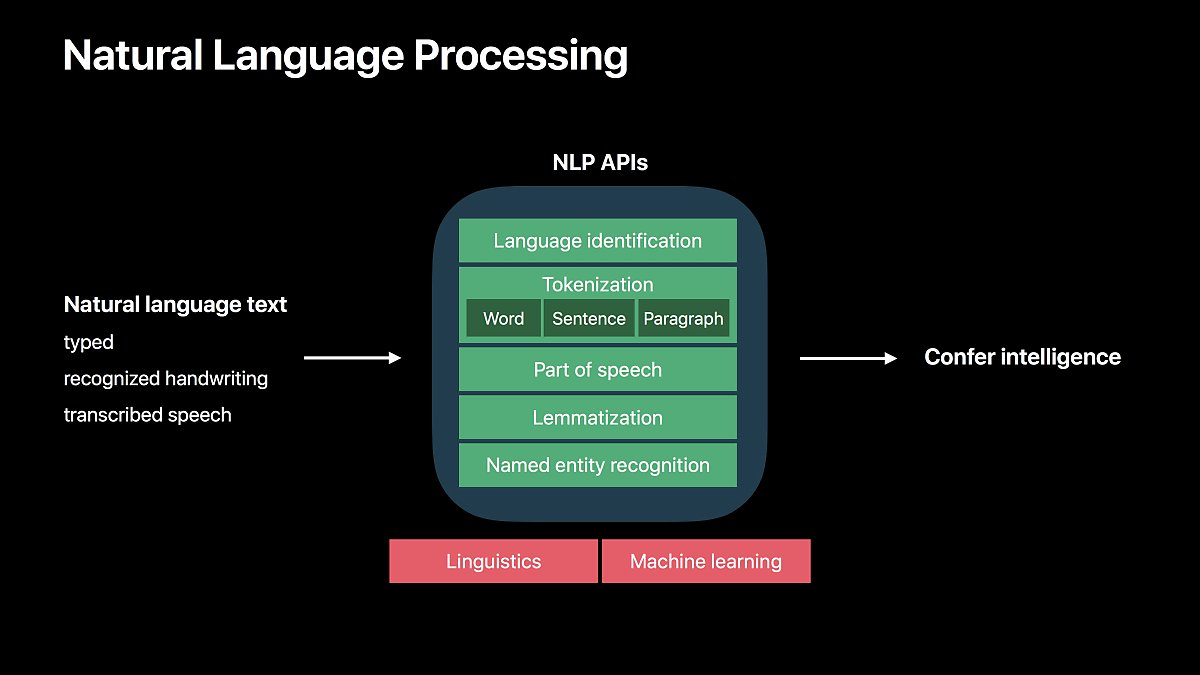
자연어 처리는 크게 다섯 가지 기능으로 나눌 수 있습니다.
-
Language identification
입력된 텍스트가 어느 언어인지 판별합니다. 텍스트가 한국어인지 영어인지 프랑스어인지 알 수 있습니다.
-
Tokenization
입력된 텍스트를 단어, 문장, 단락 등으로 분리할 수 있습니다.
-
Part of speech
문장을 품사 단위로 나눠줍니다.
-
Lemmatization
단어의 기본형을 알려줍니다.
-
Named entity recognition
문장으로부터 사람, 기업, 지명 등의 단어를 추출합니다.

자연어 처리는 NSLinguisticTagger 클래스가 담당하며 애플의 모든 디바이스에서 사용할 수 있습니다.
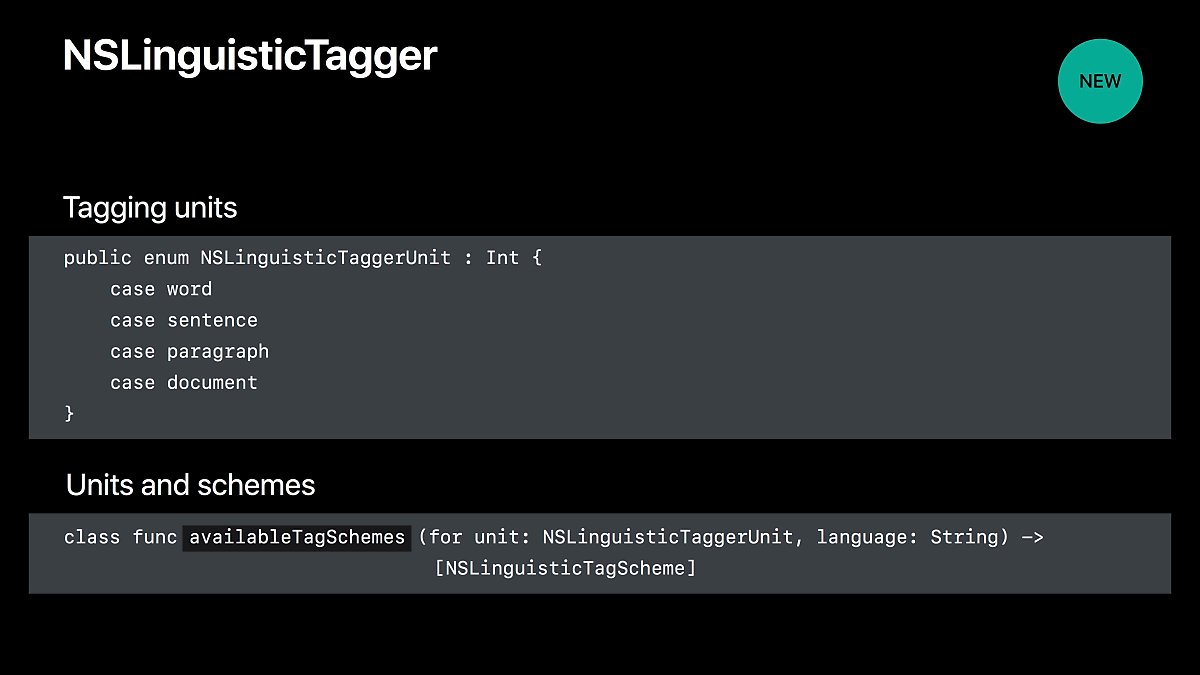
tagger unit 은 분석하는 단위를, tag scheme 은 분석할 종류를 나타냅니다.
NSLinguisticTagger 의 initializer 를 보겠습니다.
init(tagSchemes: [NSLinguisticTagScheme], options opts: Int)
NSLinguisticTagger 는 NSLinguisticTagScheme 의 리스트로부터 만들어짐을 알 수 있습니다.
NSLinguisticTagScheme 은 텍스트로부터 어떤 정보를 분석할 것인지 정의합니다.
extension NSLinguisticTagScheme {
// 텍스트를 단어 혹은 문장별로 나눠줍니다.
public static let tokenType: NSLinguisticTagScheme
// 텍스트를 품사별로 나눠서 알려줍니다.
public static let lexicalClass: NSLinguisticTagScheme
// 텍스트로부터 알려진 이름을 추출합니다.
public static let nameType: NSLinguisticTagScheme
// 알려진 이름을 분석한 후 나머지는 품사별로 분석합니다.
public static let nameTypeOrLexicalClass: NSLinguisticTagScheme
// 단어로부터 기본형을 분석합니다.
public static let lemma: NSLinguisticTagScheme
// 입력된 텍스트의 대표 언어를 분석합니다.
public static let language: NSLinguisticTagScheme
// 언어의 ISO 15924 스크립트 코드를 분석합니다.
public static let script: NSLinguisticTagScheme
}
NSLinguisticTagger 를 초기화할 때 현재 분석해야 하는 항목만 넘겨주는 것이 성능을 위해 중요합니다.
현재 분석해야 될 텍스트에서 가능한 tag scheme 이 어떤 것인지 알아보려면 다음 함수를 사용합니다.
class func availableTagSchemes(for unit: NSLinguisticTaggerUnit, language: String) -> [NSLinguisticTagScheme]
tagger unit 별로 분석이 가능한 tag scheme 은 다음과 같습니다.(영어 기준)
word -> all
sentence -> language, script
paragraph -> language, script
document -> language, script
안타깝게도 한글은 아직 language, script, tokenType 만 지원됩니다. 품사별 분석이나, 기본형 가져오기, 알려진 이름 가져오기 등을 할 수 없습니다.
이제 예제를 통해 자연어 처리를 어떻게 활용할 수 있을지 알아보겠습니다.
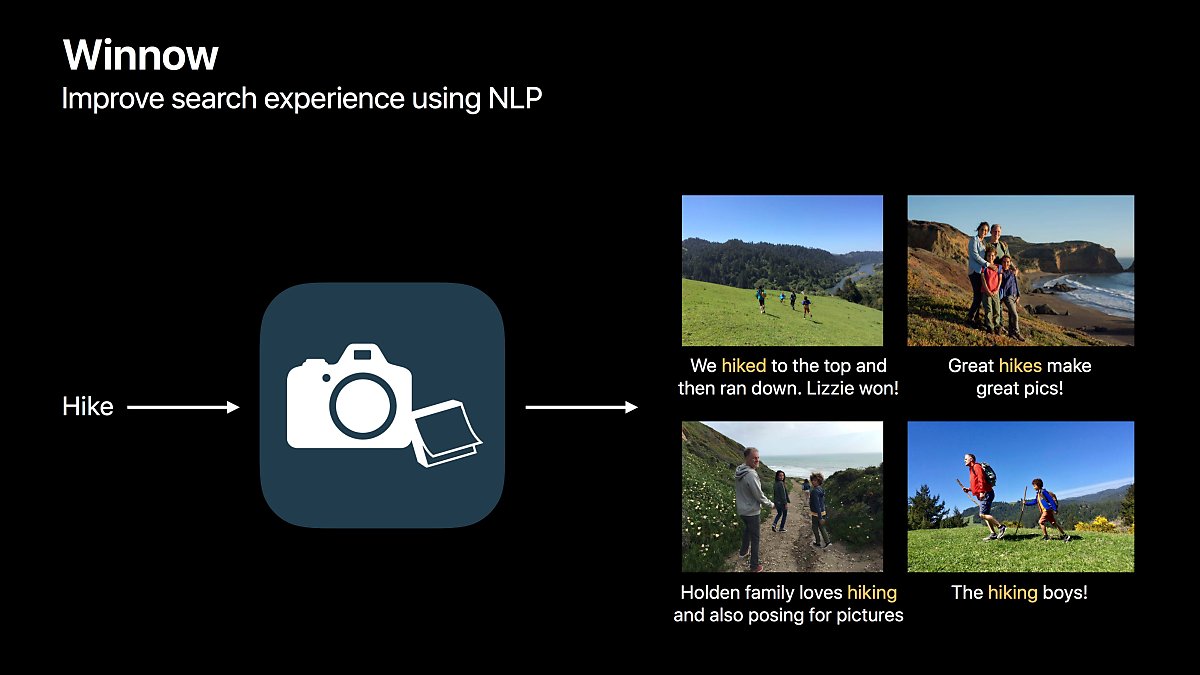
코멘트를 남길 수 있는 사진 라이브러리 앱입니다.
자연어 처리를 통해 검색을 좀 더 파워풀하게 만들 수 있습니다.
이 앱은 자연어 처리 이전에는 코멘트 문장을 단어별로 나눠서 저장해둔 후 입력된 텍스트와 비교하여 검색을 하고 있습니다.
사용자는 hike 라는 단어를 검색하려고 하는데요. 코멘트에 이미 hiked, hikes, hiking 등 hike의 변형 단어들이 많이 들어있지만, hike 라는 검색어로는 해당 사진들을 찾아내지 못하고 있습니다.
자연어 처리를 이용해서 모든 단어들의 기본형을 검색 데이터에 추가함으로써 검색을 좀 더 잘 할 수 있게 됩니다.
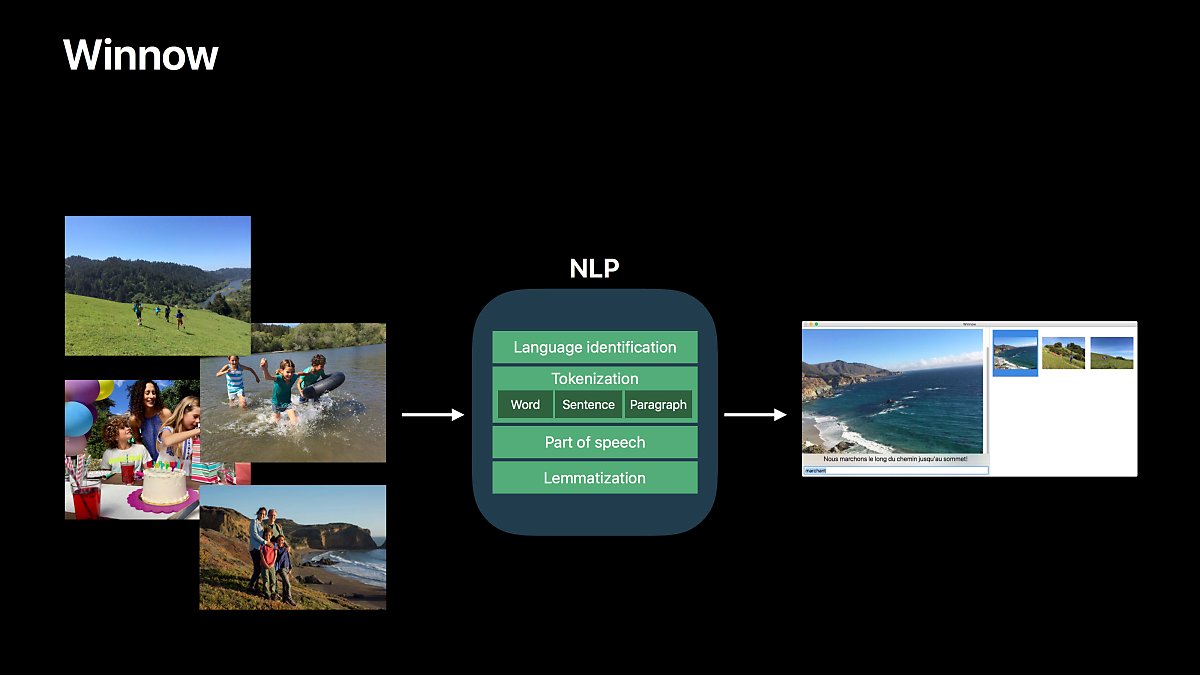
우리가 원하는 자연어 처리를 위해서는 다음과 같은 과정을 거쳐서 원하는 단어를 추출합니다.
- 언어를 인식합니다.
- 단어별로 분리해냅니다.
- 기본형이 있는 단어를 찾아냅니다.
이 과정은 아래와 같은 코드로 표현됩니다.
func setOfWords(string: String, language: inout String?) -> Set<String> {
// 검색에 쓰일 단어들을 저장할 변수
var wordSet = Set<String>()
// 자연어 처리를 언어 인식, 기본형 추출에 사용합니다.
let tagger = NSLinguisticTagger(tagSchemes: [.lemma, .language], options: 0)
// 분석 범위는 입력되는 텍스트 전체입니다.
let range = NSRange(location: 0, length: string.utf16.count)
// 분석할 텍스트를 NSLinguisticTagger에 알려줍니다.
tagger.string = string
// 분석할 텍스트의 언어를 직접 알려주거나, 분석된 언어를 얻습니다.
if let language = language {
// 분석할 텍스트의 언어 정보가 있을 경우 강제로 지정해줍니다.
let orthography = NSOrthography.defaultOrthography(forLanguage: language)
tagger.setOrthography(orthography, range: range)
} else {
// 분석할 텍스트의 언어 정보가 없을 경우 호출한 쪽에 알려줍니다.
language = tagger.dominantLanguage
}
// 입력된 텍스트를 word 단위로 토큰화 하고 lemma(기본형) 정보를 얻어와 enumeration 합니다.
// 분석할 때 구두점이나 빈 칸은 제외합니다.
tagger.enumerateTags(in: range, unit: .word, scheme: .lemma, options: [.omitPunctuation, .omitWhitespace]) { tag, tokenRange, _ in
let token = (string as NSString).substring(with: tokenRange)
// word 단위로 추출한 텍스트를 저장합니다.
wordSet.insert(token.lowercased())
if let lemma = tag?.rawValue {
// 기본형이 있을 경우 이 단어도 저장합니다.
wordSet.insert(lemma.lowercased())
}
}
return wordSet
}
다음은 간단 예제 코드들입니다.
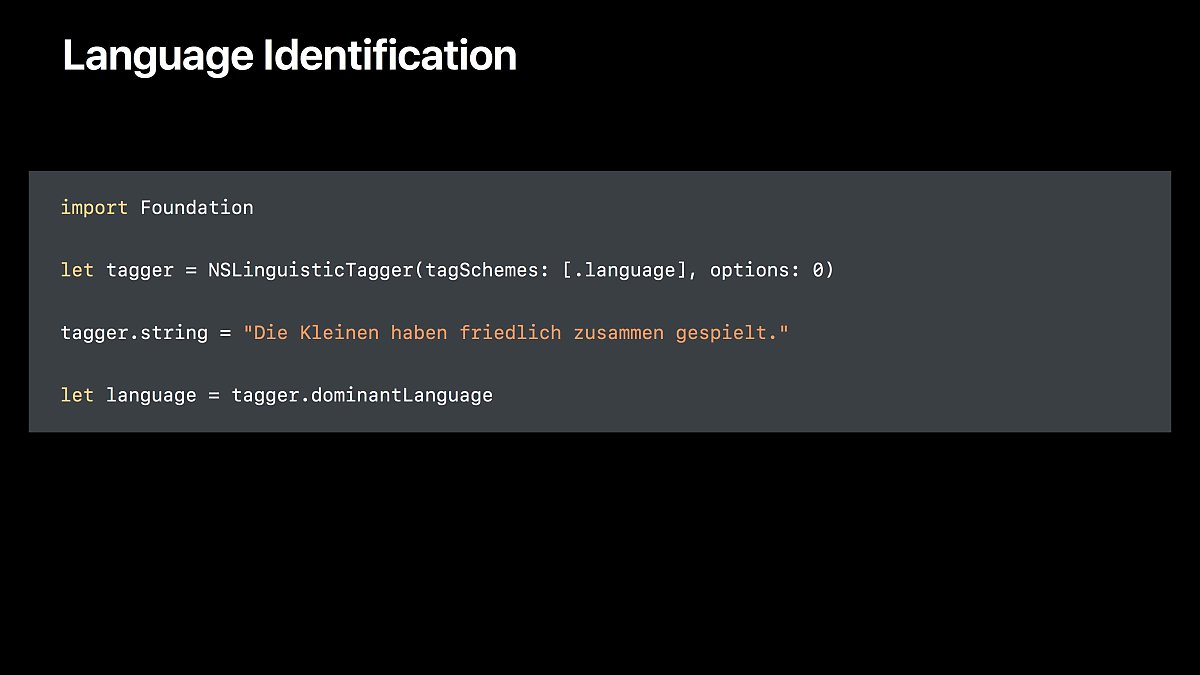
언어 종류 인식하기
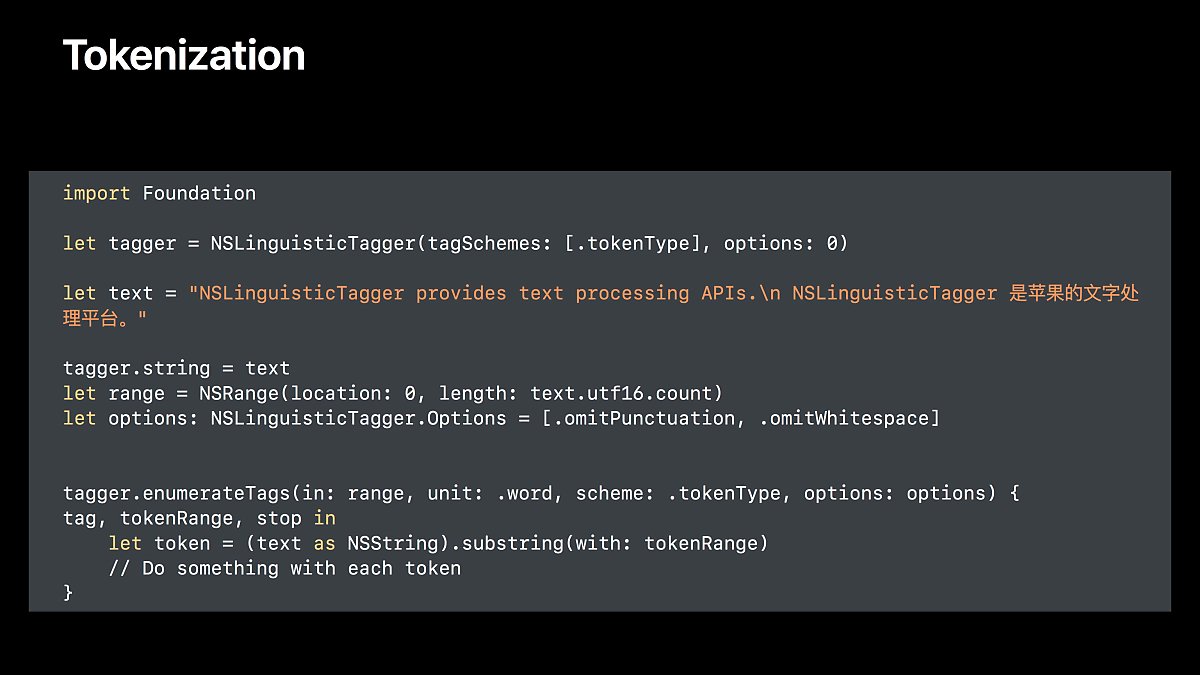
단어별로 텍스트를 나누기
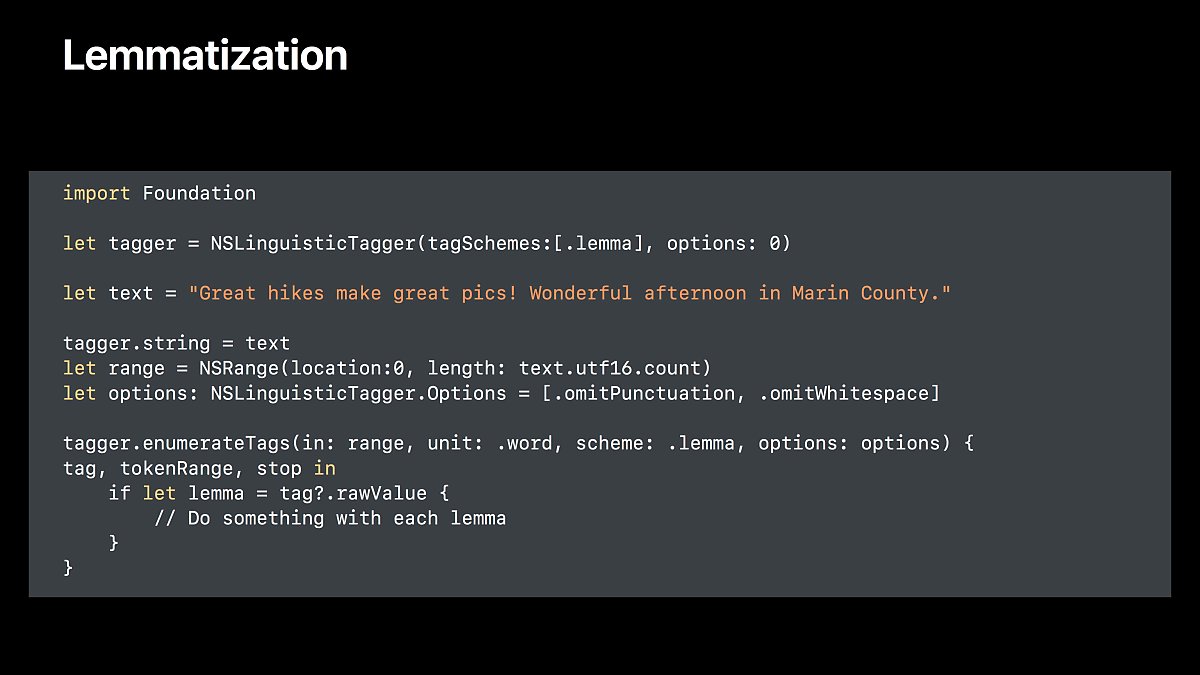
기본형이 있는 단어만 추출하기
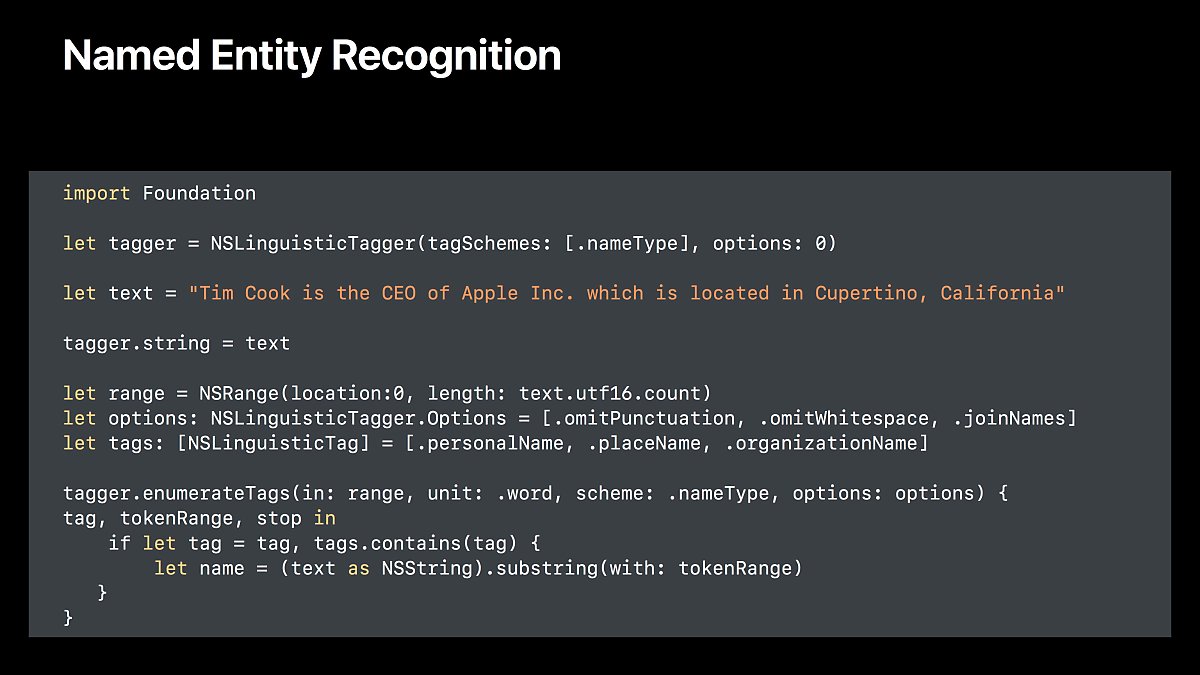
이름, 장소, 기업명 추출하기
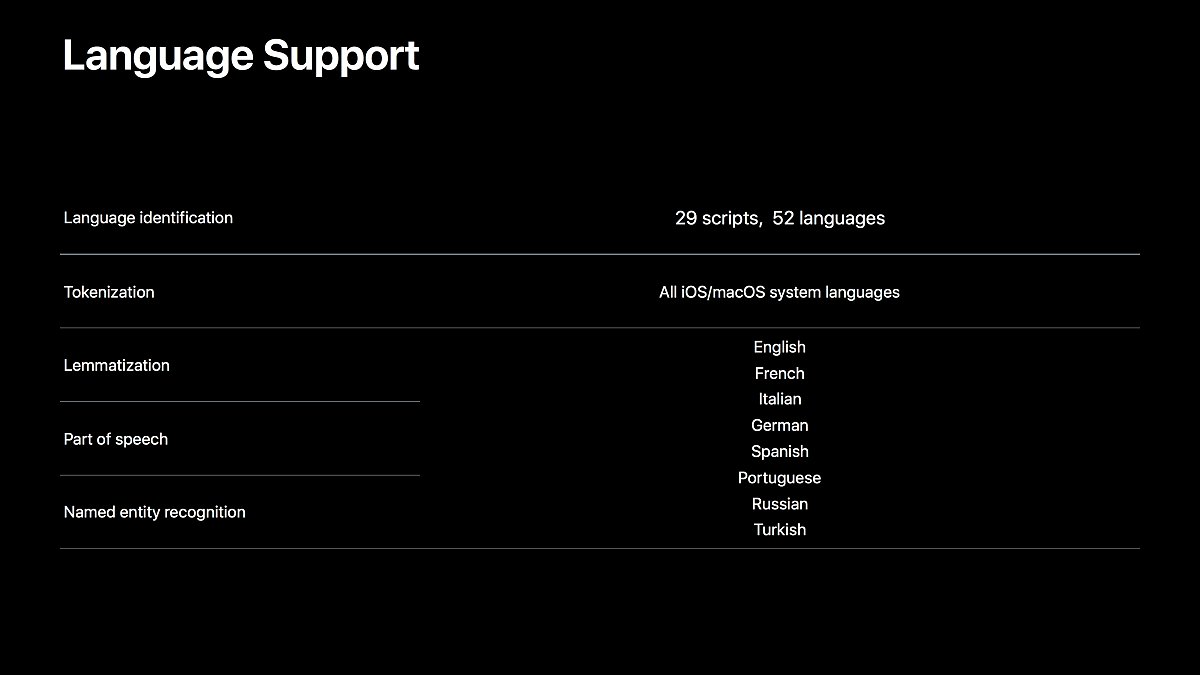
자연어 처리 종류별로 지원하는 언어들입니다.
언어 인식이나 토큰화 하기는 한글을 포함한 대부분의 언어들에서 지원하지만, 좀 더 유용하게 쓰일 다른 기능들은 아직까지 서양권의 몇 가지 언어만 지원하고 있습니다.
최대한 빠른 시간 안에 한글도 지원되기를 기대합니다.

몇 가지 개발팁입니다.
자연어 처리 중 결과로서 NSLinguisticTagOtherWord 가 나올 수 있습니다. 이건 알 수 없는 품사일 때 나올 수도 있지만, 머신러닝 데이터가 부족하거나 해당 언어의 머신러닝 모델이 다운로드 되지 않아서 일 수도 있습니다.
업데이트되는 모델은 OTA 를 통해 업데이트됩니다.
설치가 안 된 언어의 모델은 해당 언어의 키보드를 설치함으로써 머신러닝모델도 설치할 수 있습니다.
가능하면 어떤 언어인지 셋팅해주세요. 다른 언어지만 같거나 비슷한 구조의 언어들이 있기 때문에 해당 텍스트의 언어가 무엇인지 확실하게 알고 있다면 셋팅해주는게 좋습니다.